Stop Saying 'AI Is Like a Junior Associate': Looking at the Sullivan & Cromwell Hallucinations.
In the wake of the Sullivan & Cromwell AI hallucinations in a New York Chapter 15 Bankruptcy case, I am once again seeing a common trope that AI is 'like a junior associate.' No, it isn't!
In the wake of the Sullivan & Cromwell AI hallucinations in a New York Chapter 15 Bankruptcy case, I am once again seeing a common trope that AI is “like a junior associate.” No, it isn’t!
“Supervising AI is no different from supervising junior lawyers or allied professionals.” Clio, ABA So says an article by Clio on the ABA website in Law Technology Today from January 2026. This is not correct! Supervising AI is very different! They are hardly the only source for this claim. Go look at the X/Twitter or LinkedIn discourse around Sullivan & Cromwell and you’ll see it everywhere.
Why do I care? Because metaphors shape how we operationalize our knowledge. This is a bad metaphor that fundamentally misunderstands how LLMs go wrong. In this post, I will give you some better metaphors to remind you of the real risks of using LLMs in legal work and explain why using the “Junior Associate Metaphor” can make those risks harder to spot.
Terminology: large language model (LLM) not the legal degree; “AI” discussed here as shorthand is more accurately “generative artificial intelligence,” one type of the broader category of AI; “frontier models” are the most advanced generative AI models.
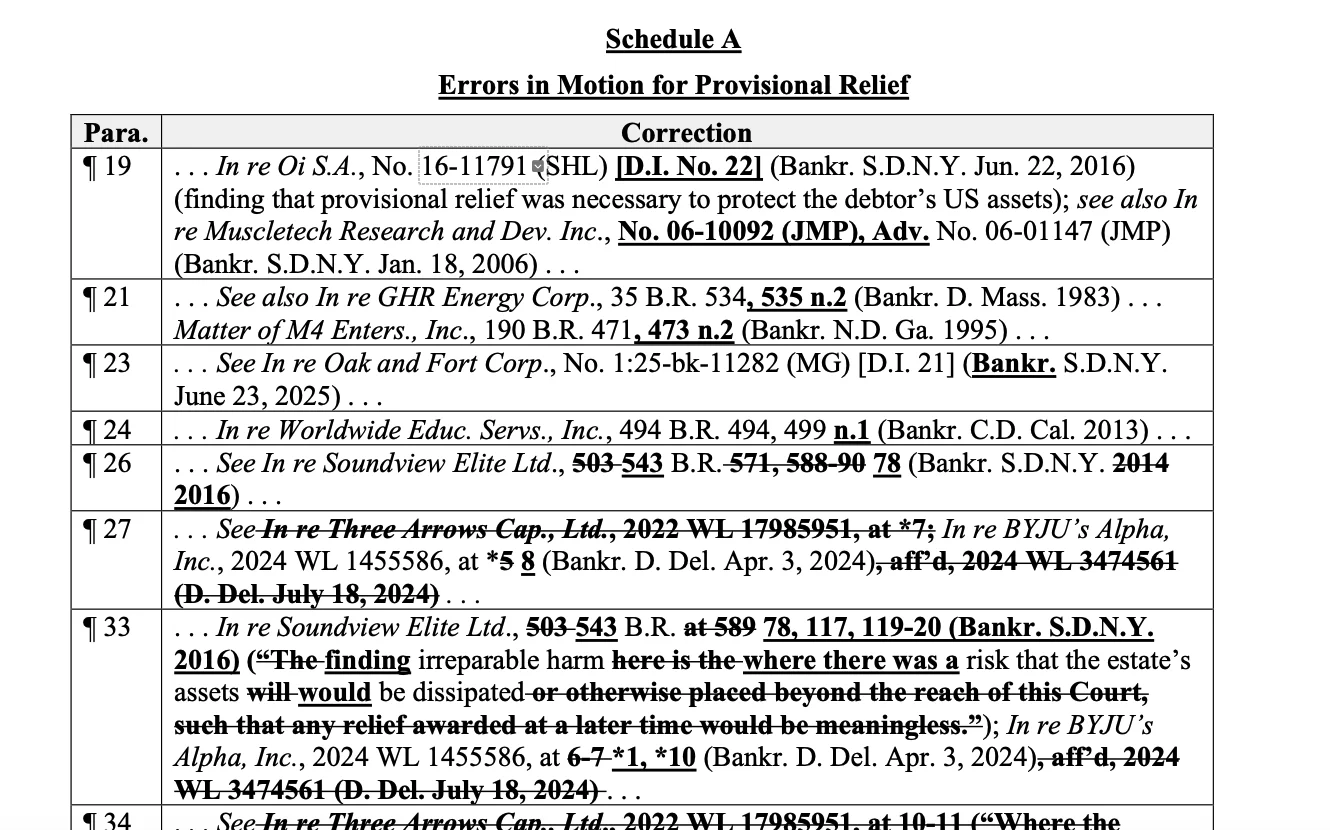
If you rely on the Junior Associate Metaphor, you are likely to repeat the same mistakes as Sullivan & Cromwell at some point if you use AI regularly. Just look at the mistakes in their Schedule A: changed verbatim quotations, including major addition of wording, minor deletion or addition of words, unnecessary use of ellipses and brackets, and changes in capitalization; apparently hallucinated citations (e.g., “In re Three Arrows Cap., Ltd., 2022 WL 17985951”: more on this in “Mutant Citations” section below); and arbitrary changes to reporter numbers or years in otherwise correct case citations.
This was a process failure across several documents, not just a simple mistake limited to one filing:
- Errors in Motion for Provisional Relief
- Error in Verified Petition
- Error in Motion for Joint Administration
- Errors in Motion for Entry of an Order Scheduling the Recognition Hearing
- Errors in Declaration of Andrew Chissick
- Errors in Declaration of Paul Pretlove
I explicitly warned about this and even have an educational game that I created to educate attorneys about these exact failure modes.
Silently Making Material Changes In the Last Edit
If you hand a document to a junior associate for a final read-through to check wording, flow, formatting, typos, grammar, that is what they will do. The cites have already been checked. The quotations are done. The content is there. It is just cleanup. You cannot trust an LLM to follow those instructions, and this is one of the biggest problems with the “junior associate” analogy. I made a game to illustrate this problem; the AI writing problem was relevant in a case in a state Supreme Court case; and a recent research paper, “LLMs Corrupt Your Documents When You Delegate,” confirms what I have been teaching in my CLE courses.
For more, see this interactive game I made to demonstrate this exact failure mode: The AI "Writing Help" Trap. I also discuss this in my CLE On Demand catalog.
Better Metaphors: Japanese point-and-call and the Glass Donut Machine
Here is my metaphor: AI is like a Japanese train and you are the operator. You point-and-call everything. Instead of pointing at your instrument readings, you are pointing out and saying the material details like quotations, parties, and citations out loud and navigate to each source one last time. This is the very last thing a human does before the document is submitted (I really mean last as in the final person touching the document, no Copilot or Claude “just clean this up” afterwards LAST MEANS LAST).
Now, the Clio ABA article I mentioned earlier also talks about pilot checklists, but it barely develops this as a metaphor. Even though the article is ostensibly about the checklist, it leans heavily on the inapt Junior Associate Metaphor. And the Clio checklist itself points out things that human junior associates do not do, like blending jurisdictions (more on that in “mutant citations” below).
Do you find this level of deliberate, checklist-based review too tedious and time-consuming? Then here is my second metaphor. I have a machine that makes delicious donuts instantly and for free. Only problem is, I think one in every few batches has broken glass in it. That’s OK, “you just have to check…by tearing apart every single donut to look for the tiniest bits of glass?” But that is very time-consuming and ruins the donuts. “I guess we’ll just keep eating them, since no one has died yet.” Or maybe (crazy thought) you stop using that machine and go back to making donuts the old-fashioned way.
Now I’m absolutely not saying AI has to be perfect, nor am I anti-AI. But AI workflows can be considered to save time if and only if they save time after you account for the time it takes to properly check outputs, especially for catastrophic failures. In the case of Sullivan & Cromwell, the case In re Prince Global Holdings Limited is a multi-billion dollar pig butchering scam bankruptcy. It is possible that the case could be delayed due to the hallucinated citations (DOJ indictment of Prince Group chairman; S&C filing, April 18, 2026).
You Cannot Just Check Formatting As a “Dipstick Method”
If the associate is mistaken and doesn’t know what to do because they’re out over their skis, they are probably also going to make formatting errors, or factual errors, or come and ask questions. Because they are not going to know what they should do. Their draft is not going to look right. It is not going to sound right. Because the associate does not have the knowledge or the skill. The associate is going to hit certain limits.
To check your car's oil, you use a dipstick. It doesn’t directly show you the level of the oil, but rather how much oil is on the dipstick. Usually, this is a good proxy for what is in the car. Before LLMs, a senior attorney might have gotten away with skimming a human-prepared document for formatting. The outward signifiers of correctness (italics, special characters, spelling Latin words, using legal terms of art) would all correlate closely with the associate’s actual background knowledge and the diligence that went into preparing the document.
That formatting check might have worked (most of the time) prior to ChatGPT for human-prepared documents. That does not mean that was the right way to do it. It is not a defense of that method. I am merely describing what may have happened. But you cannot use this Dipstick Method with LLMs. It is as if the LLM regularly dunked your dipstick in a tub of oil before putting it back in your car. Now, the dipstick is back in your car, but it is not a reliable indicator of your oil levels. And having someone remind you “you have to check it” is not helpful advice.
Unlike the associate, generative AI has a jagged frontier of knowledge, where LLMs excel in some difficult areas, and fail foolishly in other simple areas. Therefore, if what the senior attorney is actually checking for is not the correct thing itself (e.g., quotation, citation), but the proxies for the correct things, like formatting—Is this italicized? Is the “section” symbol used? Did they have reporter numbers?—we see senior attorneys in these AI hallucination cases time and again signing off on stuff that looks good. Sometimes not just passable but looking really good. Again: “looks good,” but it is actually not correct.
Sometimes people will defend LLMs by saying lawyers have been cutting corners on review since before LLMs with these cursory formatting reviews. Or lawyers have been citing cases without having read them closely since before LLMs. This is the wrong conclusion. These tools are becoming ubiquitous and are causing what Damien Charlotin aptly called “Polluting the epistemic commons.” The rate at which these errors spread is growing and they will compound as the LLMs cite each other's errors, embellish errors, and create their own novel errors. This is a positive (but bad) feedback loop of polluted legal information as these citations get baked into ostensible “good” case law.
Before LLMs, the “Dipstick Method” was probably good enough—or at least good enough that the people doing it did not get caught. But, LLMs are laying bare some old bad practices that were not OK to begin with and are much more harmful now. Now that we have LLMs, it is more important to hold the line on the older rules that should have been followed all along. To use a different car analogy, drunkenness was a problem before widespread private automobile ownership, but drunk driving significantly compounded the damage a drunk could do to others.
S&C apparently had the right policy, but...
S&C stated that its “training repeatedly emphasizes the risk of AI ‘hallucinations,’ including the fabrication of case citations, misinterpretation of authorities, and inaccurate quotations. It instructs lawyers to 'trust nothing and verify everything’ [emphasis added] and makes clear that failure to independently verify AI-generated output constitutes a violation of Firm policy. The training also reviews the significant consequences of AI-related errors in various cases.”
Further, “the Firm’s Office Manual for Lawyers...provides that lawyers 'must independently check all answers, case citations, and other information or work product received from an AI Program for both substantive and non-substantive accuracy.’ [emphasis added] The policy further states that no communication may be sent to a court, regulator, client, or other external party without the exercise of appropriate professional judgment and oversight. Notwithstanding these safeguards, the Firm’s protocols were not followed here.”
Trusting nothing and verifying both substantive and non-substantive accuracy seem to fit my advice. They seem to be saying not to let proper formatting and fancy wording trick you. Yet that was not enough. Why? I think the reasons are likely because a) attorneys are still not exposed to the specific ways that LLMs can hallucinate, because without exposure to convincing hallucinations that are hard to spot, naive users can be overconfident in their ability to spot hallucinations; and b) we default to metaphors, and the dominant metaphor for supervisors is the “intern” or “junior associate,” which is wrong in specific ways that lead attorneys to miss LLM hallucinations.
Mutant Citations
LLMs will hallucinate based on nothing (ungrounded hallucinations). A human might do this occasionally. They might bluff. But they won't be able to sustain it with endless detail. An LLM can indefinitely and arbitrarily extend a fake scenario: because that's what they do. So if you keep pushing the point, the associate will give up. The LLM won't.
Most of the attention gets focused on purely hallucinated cases. Cases that simply do not exist. But a bigger risk is what I refer to based on the words of a judge in the Eastern District of Michigan as “mutant citations”. These are amalgamations of real cases stuck together by the LLM. Maybe the name of a real party from one real case and a second party from a different real case. Maybe it is a federal case mixed up with a state case in the same state or region. Maybe it is the name of a real case but the wrong jurisdiction and the wrong year.
When a human cites a case and the senior attorney sees it has Bluebook formatting, a Westlaw reporter number, proper italics for Latin, uses legal terms of art, has quotations, etc., the assumption is that the document must be correct. “The associate must have actually looked at the cases. Nobody would just make that up.” A human wouldn't.
Remember that hallucinated case I mentioned from Sullivan & Cromwell: “In re Three Arrows Cap., Ltd., 2022 WL 17985951”? Well Three Arrows Capital was a real cryptocurrency company that collapsed, along with several others in 2022. It is a realistic party with a realistic year that would be relevant to a bankruptcy involving pig butchering scams, which typically transact in cryptocurrency.
And, of course, it made up Westlaw numbers. For comparison, take a look at this case from December 27, 2022 on the DOJ website: “Woodward v. USMS, No. 18-1249, 2022 WL 17961289 (D.D.C. Dec. 27, 2022) (Contreras, J.).” See the DOJ OIP summary. As far as I can tell, there is no real case with “2022 WL 17985951”; the results on Google show Damien Charlotin’s AI Hallucination Database and a link for the Sullivan & Cromwell filing in PACER. But it is pretty close to the numbers at the very end of 2022. It would be impressive, even shocking, for a junior associate in 2026 (who, for all we know, might’ve been in undergrad in 2022) to shoot from the hip with a WL number in the right ballpark for an end-of-2022 case, but not an actual case.
In fact, it gets more specific. The real Three Arrows Capital case was a Chapter 15 Bankruptcy case under the same judge (Chief Bankruptcy Judge Martin Glenn) as the Prince Group case, both in the Southern District of New York.
Remember that Clio ABA article I mentioned earlier? The checklist has reminders that hint at the possibility of mutant citations, even as the article keeps pushing the unhelpful analogy of supervising a human employee.
6. Confirm the correct jurisdiction General AI frequently blends jurisdictions. Ensure the content reflects the correct federal, state, provincial, or local law, including terminology and standards. 7. Look for bias or mischaracterization Check that cases are accurately described and not selectively framed. Generative AI can reflect bias from training data if left unchecked.
But does such a checklist give you the remotest sense of how almost-correct the AI can be when it hallucinates? You could “confirm the jurisdiction” and still not catch that the particular case citation as written was a hallucination.
If humans erred the way AI does, we’d call it “fraud”
A human associate typically does not say, “Oh, I found an on point case, but it's in the Fifth Circuit. We're in the Seventh Circuit. So what I'm gonna do is I'm just gonna change the citation, to this real case, and say that it was in the Seventh Circuit. And wherever it says, ‘Texas,' I'm gonna say, 'Illinois.' And wherever it says, ‘Louisiana,' I'm gonna say ‘Wisconsin.' And I'll make up some names and change the details to be consistent with that new geography.” A junior associate does not do that. An associate typically does not have the capacity to fabricate that many details. For LLMs, it’s what they do.
However, if the associate did do that, you would take that as alarming, fraudulent behavior. Most likely, you would not call that a simple “mistake.” It is probably something you would want to discuss internally at your firm for disciplinary measures or potentially even the Bar. That is not the kind of deceptive behavior you want from your employees.
You probably don’t need to worry about that, though. Somebody who is phoning it in and not really doing the work is probably not going to go through the trouble of writing a detailed fake scenario like this. An associate will more likely do a bad job that looks like a bad job. Or ask for help or do a good job.
Arbitrarily detailed: Surprisingly voluminous falsehoods
But for the LLM, it is trivial to make up details. That is why in the infamous Mata v. Avianca case, the attorneys did not only cite fake cases but provided the supposed text of those fake cases to the Court after the opposing counsel (Avianca) said they could not find the fake cases supposedly about airlines (their area of expertise).
If, like the Mata attorneys, you ask an LLM to provide the text of a case that does not exist, it might continue to bluff and hallucinate the entire text of the case. The more you drill down within the LLM itself, the more detail it gives. But it’s all fake! You have to remove yourself from the AI tool and actually navigate to the primary source, not a chatbot or AI summary: and I do include Google and the legal AI tools in this list. A junior associate simply won’t spit out pages and pages of six fake cases off the top of their head when pressed to defend a bad citation.
Verisimilitude: Surprisingly accurate falsehoods
Another surprising thing I have observed is when LLMs make up cases, the reporter numbers can be shockingly close to the right thing. They might be close to an unassigned number. It doesn't correspond to a real case. But it would fall into that range for the jurisdiction, for the state, for the year, if that case had existed.
A junior associate is not going to be able to do that off the top of their head. They are not going to be able to make up a number. They are not going to be able to say—and I'm going to make this up off the top of my head, so it's not going to be right—“847,” and know that that 847 is going to fall between 845 and 850, which are both real cases from the same state and year.
An associate is not going to have the encyclopedic knowledge and recall to do that. And like I said before, it is not a human mistake. If a human were capable of doing that, we would call it deception or lying, not a mistake. But this is the kind of mistake that frontier LLMs make.
The time it takes to check
It can take a lot of scrutiny to verify or negate these types of hallucinated citations. It will not necessarily be obviously wrong because it may not be absurd. The hallucination could be very close to the real thing, which is bad. Obviously wrong things in some sense are actually better.
This is why I frequently say that I don't like it when people say “the AI models are getting better.” Rather, I reframe it as “the models are getting more capable.” If a model is old, an incorrect case citation might have said something like Smith v. Jones (2009). That looks hallucinated. It could be a real case, but it is vague: two extremely common surnames and no jurisdiction.
If instead, it had the name of a real individual (first and last name) versus a real car dealership in Indiana, and it said that the case was in the Court of Appeals of Indiana, 2014, with a reporter number that fit with that year, it could take a lot of work to determine that citation was actually an AI hallucination.
When checking, watch out for Doppelgänger Hallucinations
Lastly, I need to talk about my Doppelgänger Hallucination tests, which I first warned about in October 2025. Basically the LLM is sycophantic and wants to tell you what you want to hear. If you ask it a question, even the question as simple as just giving it a bare case citation with no other wording, only a properly formatted fake case, may result in the LLM providing a description of that case.
If you use other AI tools to try to cross-reference your original source, you may become more convinced that the fake case is real if you are following the Junior Associate Metaphor. Maybe you google it (AI Overview), or check Gemini, ChatGPT, Claude, Perplexity, etc. Maybe some of those AI tools are telling you it is a real case. Maybe not all of them, but maybe multiple of them are saying it is real. The details they tell you about that case are probably not consistent with each other (since they are hallucinating independently). But you might go even further down the rabbit hole of “what's going on with this case?” And in the end, it's not real.
A lot of times, the LLM likes to tell you it was an “important” case or a “significant” case. It will make up descriptions of the fake case and tell you it was a major case that perhaps “set a precedent” or “is frequently cited.” All of that is not true.
In my Kruse v. Karlen test, I used the 22 known fake citations from the reference table. Searching for only the citations in quotes, the Google AI Overview gave an inaccurate answer describing the fake case as real—despite having access to a source explicitly calling it fictitious—roughly a quarter of the time; this rate rose to over half of the time if the user opted for “AI Mode.”
This phenomenon of another LLM corroborating a fake case is not a hypothetical. This has happened to real attorneys where they've double-checked and triple-checked using multiple LLM-powered tools.
An associate does not usually do that. Even if they did, they cannot sustain that level of embellished fabricated detail off the top of their head. It's just not how people work.
AI is not like a junior associate. Treating it like that can result in a three-page single-spaced list of corrections, with possibly even more errors being spotted by opposing counsel.