Ideas Notebook: FrontierListBench OSINT Enumeration Benchmark with Human Judges

This is an initial idea and I’m not fully ready to implement it, but I have the outlines of an idea forming.
Think of a task that has many correct answers that are verifiable, but difficult; for example: How many law firms are there in Iowa? How many gas stations are there in New York City? How many coffee shops are there in Polk County, Florida? These are technically knowable, but very difficult to list exhaustively.
Generally speaking, the answers should be verifiable using open-source information. The challenge is that this would be incredibly time-consuming for human verifiers. My solution would be to have multiple LLMs compete, with unique answers scored at a higher multiple by the human reviewers (e.g., think of how you score only unique words in the game Boggle). Consensus answers would be presumed correct but scored lower (note: this could be a mistaken assumption, but acceptable for the purposes of scoring).
Scoring would be normalized during the first run with the “best” model = 100 (kind of like CPI for the reference year). Then, the scores for later generations of models could be scored relative to that. Additionally, there would be a secondary score for models finding things other models didn’t find, even if they performed worse overall, which would show complementarity. See the chart below to get a sense of what I mean.
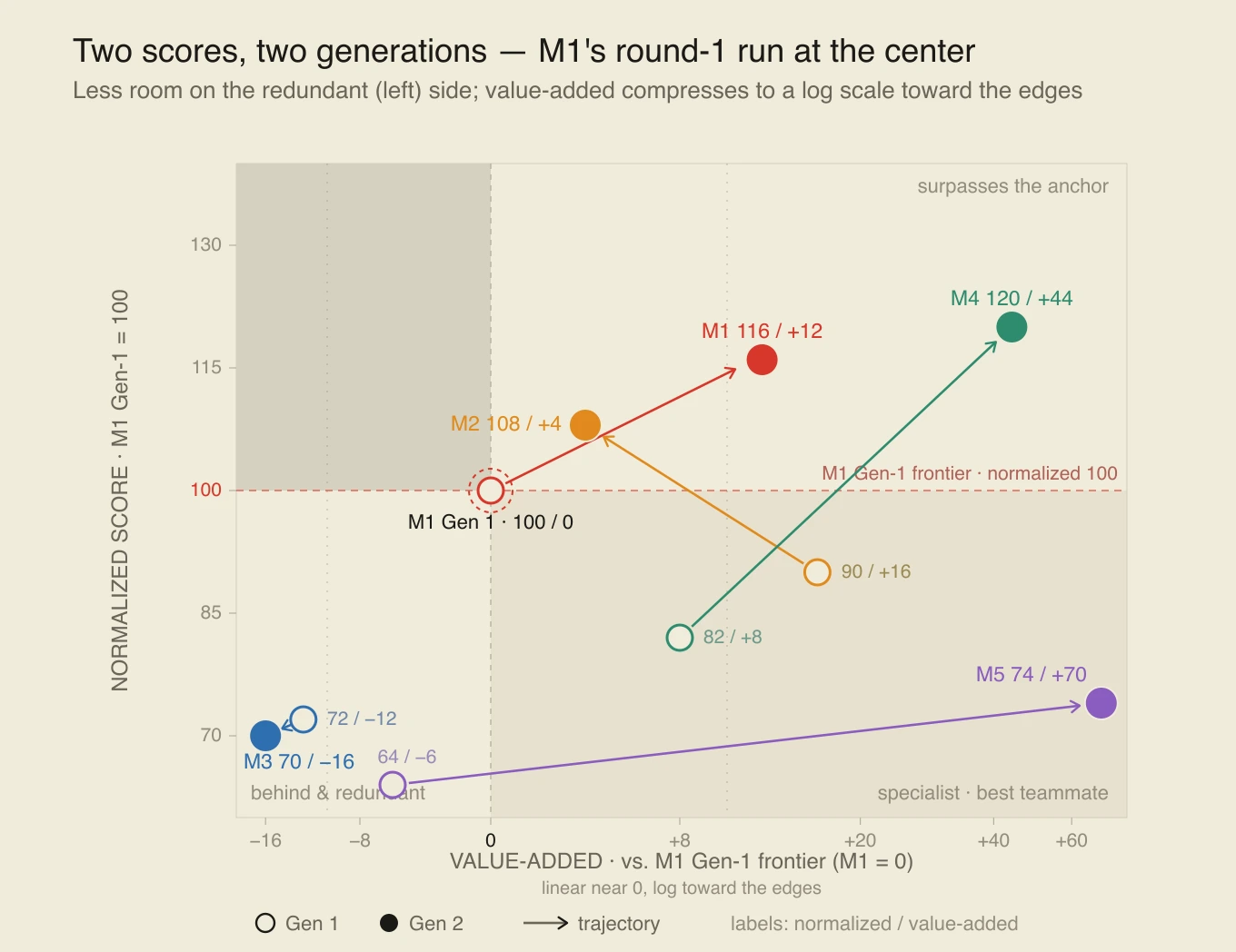
Made up numbers explaining how the two scores in the FrontierListBench (or whatever I eventually name it) behave: the best model in the first reference generation is 100 and can’t add anything to itself by definition; a model can rank lower overall yet still be the best teammate by finding what others miss (bottom-right), while two top models can converge and turn redundant (top). Higher scores will inherently move both up and to the right. M1's first run is normalized to 100 at the center.
Scoring Challenges
- What happens if a model hallucinates incorrect answers? Is this a negative point? Perhaps, but then a model with few correct answers would score low positive numbers while another model with many correct answers and several hallucinations might still have a negative score. In that case, we’d have to understand that the benchmark would be biased in favor of models that abstain from answering, rather than models that attempt to be comprehensive but still make errors.
- Correctly bucking the consensus would be penalized: e.g., if Model A and Model B list a coffee shop that shut down, but Model C correctly recognizes that that shop is no longer active and does not list it, this scoring model would penalize the correct Model C as missing a consensus answer.
Other Challenges
- Contamination from the benchmark: after writing about this benchmark, LLMs may find earlier posts and use those answers for future tests. This is partially mitigated by rotating the question set. For example, if I ask about law firms in a particular county, the next time, I could sample from a comparable county based on socioeconomic statistics or the presence of a courthouse, or some other pre-determined factor, but not repeat the same county. Scores would be normalized on a scale of 100.
- Contamination from other sources: asking about something with a well-known source (e.g., Damien Charlotin’s hallucination database; a popular Wikipedia page enumerating certain things) may result in the LLMs simply copying that list.
