It’s Not Just GIGO: Don’t Dunk on the Dakotas and the Data Was Not the Problem

TL;DR
- N.D./S.D. can mean “Northern District” and “Southern District” for federal cases, overlapping with “North Dakota” and “South Dakota” postal abbreviations; other states have possible issues here like MD and OK
- “CA” (Court of Appeals? California?). I addressed this in my “Writing Help” game.
- “SC” is a triple threat: South Carolina, Supreme Court, or Superior Court?
- I looked at the data. Yes, there were some human errors, but it is clear that Charlotin has put in the work to create and maintain this valuable resource. That’s why I think people find it worthwhile to send him cases. He’s provided something of value and put in the time. Anyone who looks closely at the data can see that. People who churn out slop reports, on the other hand, are wasting your time. If it wasn’t worth their time to write, why would it be worth your time to read?
- Once you account for relative population, the map is much more of a dog bites man story. To me, the more interesting part is the specifics of each case and the citation graph of cases that are frequently cited by later cases in these disciplinary decisions.
- For example, I thought this may have been a mistakenly coded jurisdiction but it was not: Lowery Wilkinson Lowery, LLC, et al. v. State of Illinois, et al. (E.D. Oklahoma 2025). Instead, it’s an interesting attempt by the plaintiff to apply the “Indian Country” McGirt ruling and the plaintiff also misattributed that U.S. Supreme Court ruling to the Eastern District of Oklahoma Judge.
- “There is no one righteous, not even one.” After data cleanup, New Hampshire alone seemingly had no hallucination cases, but I found both that New Hampshire had had its own hallucination case around July 2025 per reporting last fall, and that a New Hampshire attorney had been responsible for hallucinations (actually from the client) in a case in the Vermont Supreme Court.
“N.D.” and “S.D.”: Did Not (Usually) Mean the Dakotas
Damien Charlotin maintains a well-known public database of AI hallucination cases around the world. It has even been cited in a legal case here in Iowa. I’ve written about his work before, including his point about low false-positive rates potentially creating automation bias, lulling users of legal AI tools into a false sense of security. Recently I saw a post on LinkedIn, in which Charlotin, reacting to a report by Straight Arrow News on a study by “Laine AI,” criticized the claim that AI-driven legal hallucinations are especially concentrated in North Dakota and South Dakota. Charlotin pointed out that this was most likely due to a misinterpretation of “N.D.” and “S.D.”—common abbreviations in federal cases indicating “Northern District” and “Southern District.”
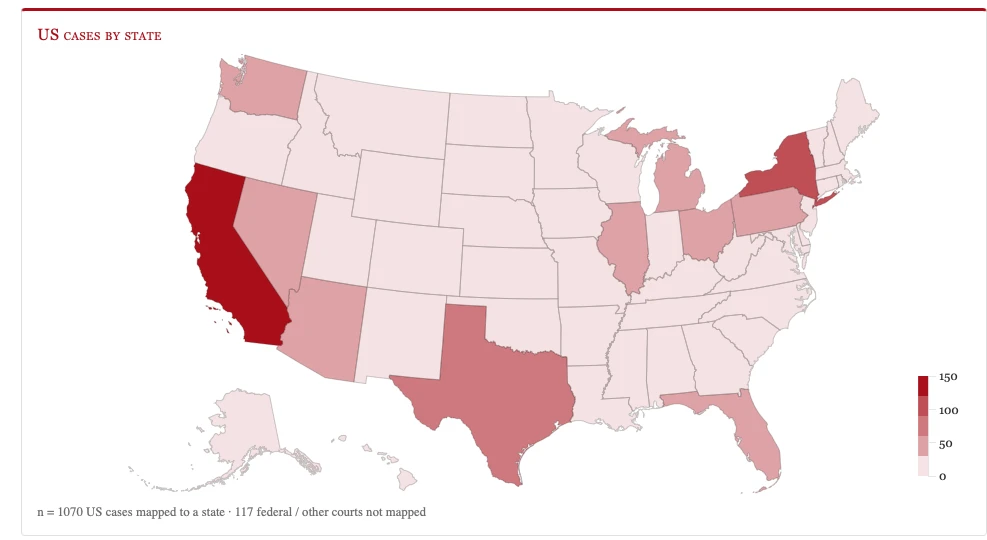
The June 19, 2026 article noted how surprising the result was, with the headline: “Where does the most AI legal slop come from? Not from the states with the most lawyers.” Laine AI, according to the article, stated that North Dakota courts had 109 cases with AI errors, South Dakota had 82, and California had 59. Supposedly, this was from Charlotin’s website, but as I often advise clients, this is not a good use of LLMs: pivot tables already exist!
I previously viewed the page on Laine’s own website with the statements about the Dakotas. It appears that as of July 2, 2026, they’ve corrected the numbers and they now reflect a more realistic breakdown of the states and have reworded the conclusions. I cannot speak to the accuracy of the revised version.
After I manually reviewed and coded the states for 1,145 USA cases and cleaned up data from Charlotin’s website downloaded on June 21, 2026, I found that the actual count was: California 121, North Dakota 6, and South Dakota 1. California had some “E.D. Cal” and similar, as well as two Ninth Circuit cases that were appeals from California cases, a case that was “CA SC” (Court of Appeals, South Carolina? California Superior or Supreme Court?) which was actually California; and one “CA 8th Circuit (Bankruptcy)” a federal Eighth Circuit case that was an appeal from District of North Dakota Bankruptcy.
None of these minor ambiguities would explain the large discrepancy in counts. My review of the numbers suggests that Charlotin was correct about the likely cause of the hallucinations.
You can read Charlotin’s own account of the mix-up on LinkedIn.
As a general observation, LLMs can be very helpful for speeding up human review of typos and spelling variants in data like this (e.g., “E.D. Cal,” “California,” “EDCA,” and “ED Cal.”). For this situation, I did not use LLMs and only did manual review, but I wanted to make that general observation. Good for finding typos and variants. Bad for replacing pivot tables.
That being said, 6 cases in North Dakota relative to its population size and number of attorneys does seem to be somewhat disproportionate. There, I’d argue that almost every state is probably undercounting/not catching AI hallucinations, or the hallucinations have been caught, but not reported and added to the database. In fact, this exercise led me to find some information about New Hampshire as the only (apparent) state without hallucination cases.
So, Midwest’s honor defended. Let’s move on to some other lessons.
It’s not just “garbage in, garbage out”
Sometimes you’ll hear about “garbage in, garbage out” (GIGO). As it is applied to practical deployment of generative AI in businesses and other organizations, there’s a common refrain that “the AI is only as good as the data you give it.”
I’d somewhat reframe that to say “the data quality limits how well your AI can perform.” Even with good data—company policies, solid accounting spreadsheets, detailed written reports—the LLMs can still hallucinate. LLMs can make ungrounded statements even when they have access to the correct answers, they can misunderstand details, and they can improperly combine text, among other failure modes.
Charlotin’s dataset is carefully maintained as far as I have seen, and I’ve looked through a lot of it. His database appeared to be the Laine study’s sole source of data. The Laine summary stats quoted in the aforementioned report, on the other hand, suggest AI hallucinations. These uses of AI: “AI can write this research paper,” “AI can write that quarterly report for the board,” “AI dashboards give the CEO unmediated access to perfect visibility into the organization” are actually organizationally destructive uses of LLMs. They are truthiness machines, but once you look under the hood at the data, you can tell that the summaries bear no relationship to the underlying data. Since there is no relationship, correcting the data is pointless. That’s the difference between a human-curated database—like Charlotin’s—and a slopped together dashboard or report or slide deck. Of course humans make mistakes too, and human-curated databases will have rough edges or errors, but it is worthwhile to look at them closely and help fix them because somebody who cares about the truth is on the other end.
Abbreviations Are Not Always OK
North Dakota and South Dakota are not the only examples. There is a whole class of collisions between legal shorthand and two-letter state postal codes. Here are the ones I’m aware of:
| Literal String | What it really means | Collides | Impact |
|---|---|---|---|
| ‘N.D.’ | Northern District | North Dakota | Low population, many federal northern districts, dramatic false spike |
| ‘S.D.’ | Southern District | South Dakota | Low population, many federal southern districts, dramatic false spike |
| ‘M.D.’ | Middle District (e.g., M.D. Fla.) | Maryland | More populous, fewer middle districts, mixed effect |
| ‘Ct.’ | Court (Sup. Ct., Ct. App., Dist. Ct.) | Connecticut | possible, but less frequently seen “in the wild” |
| ‘CA’ | Court of Appeals | California | Large population, hides in the noise |
| ‘S.C.’ | Supreme Court or Superior Court | South Carolina | Mid-spectrum |
Supreme Court or Supremest Court?
‘S.C.’ for Supreme Court raises a deeper problem. You still don’t know which court is highest in the given state without domain familiarity, because state court naming is not uniform across jurisdictions and “Supreme Court” is not the highest court everywhere:
- In New York, the “Supreme Court” is the trial court and Court of Appeals is the highest.
- Texas and Oklahoma each have two highest courts: Supreme Court (civil) and Court of Criminal Appeals (criminal).
- Maryland changed the naming to be more familiar in December 2022.
If there are other examples, please let me know. But my main point is that you can’t just assume based on the name.
Divided Islands
When parsing strings for the name of a state, “Hawaii” or “Hawai’i” can be written with or without the apostrophe, which can also be written as ʻokina (Unicode U+02BB), a real letter in the Hawaiian alphabet. This is actually an example of an area where appropriate use of LLMs can help, because it can be exasperating for regular expressions, especially with an unpaired apostrophe.
Look at the Data and Learn About the Domain
Anyone who has spent time with both LLMs and legal citations should recognize that “N.D.” could have multiple, conflicting meanings. Also, you should assume every map is secretly a map of population until proven otherwise. So when “North Dakota” has far more AI misuse than California, look at the rows in your spreadsheet first.
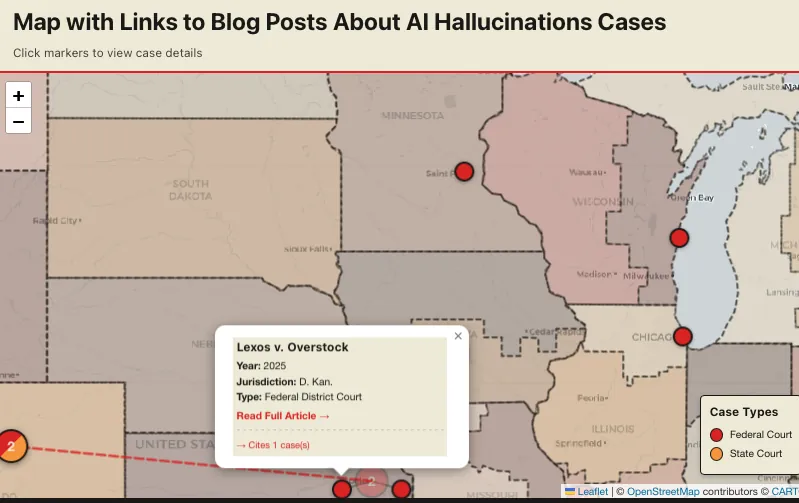
My own background is in financial-crimes investigation, OSINT, and GIS. I have hit similar failures with AI, law, and geography before, as I wrote about in December 2025 (NOTE: correction, I did this in December, but I wrote about it in January). I rebuilt my hallucination-case map with Claude Code, and at first it produced a patchwork quilt because it matched county names across states without using the state as part of the key, and there are a lot of Polk Counties. The output was obviously wrong to me because I looked at the output, and I also knew why it failed, because I’m familiar with the domain. Claude Code also tried to fabricate an Eastern and Western District of South Carolina, which is a more specific hallucination that would require domain knowledge (which I had developed), to recognize that the output was incorrect.
Nice Try, New Hampshire
After manually reviewing and cleaning/hand-coding the state data, the only state that (apparently) had no attorneys with hallucinated cases was New Hampshire.
However, I found that a New Hampshire attorney included a fake quotation from a real case in a Vermont Supreme Court divorce case provided by his client. This touches on multiple topics I want to write about, including: a) that LLMs can hallucinate quotations, so checking that a case merely exists is not sufficient; b) that client-provided AI-generated fake citations are a problem for attorneys who “don’t use AI,” so they need a reality check about Shadow AI use; and c) family law is coming up frequently for AI hallucinations (e.g., early Iowa misuse and a recent Nebraska Supreme Court case).
It wasn’t adding up. A New Hampshire attorney representing a divorce client filed a legal brief that quoted from a previous court case. But when Vermont Supreme Court justices went to the case he referenced, the quote was nowhere to be found. In a November hearing, they asked the attorney where the quote came from. “Your honor, my client used an AI, um, helper” said the attorney. Justice William Cohen, now retired, responded: “The secondary source was AI? And you didn’t identify it?” “I’m not familiar with what’s involved with it and so forth,” the attorney said. He claimed that his client offered to write the brief using artificial intelligence. The quote came from “AI GPT or something like that,” he said later on. “I didn’t use it exactly but it’s a common one, I believe.” After the hearing, justices on the state’s highest court chastised the attorney for his mistakes in a court filing, requiring him to file a copy of the write-up in all of his pending cases in Vermont Superior Court. Valley News
Later, I found a more direct example of a New Hampshire case. The “Windham case” with Judge Lisa English, reported in October 2025 involving a NH/MA attorney. I unfortunately could not track down the name of the case, despite having the attorney’s name and the judge.
The Laine report produced unsupported conclusions about supposedly excessive AI misuses in North Dakota and South Dakota. However, my analysis of the data allowed me to find the one missing gap and show that there is no state without any AI hallucination cases.
Charlotin’s Map on July 2, 2026
As of today, there is no state with 0 hallucination cases on the map of USA cases on Charlotin’s website.
Indian Country Jurisdiction: Plaintiff also claims that Judge White wrote the McGirt opinion (he did not)
Because I was manually reviewing the cases for state coding, I thought that a case with “State of Illinois” as Defendant, but in the Eastern District of Oklahoma, may have been mistakenly coded. It was not. Instead, it was interesting case and a great example of why you should look at the data and not just let AI summarize everything in the aggregate for you.
Lowery Wilkinson Lowery, LLC, et al. v. State of Illinois, et al. (E.D. Oklahoma 2025).
Multiple times, the plaintiffs attempted to raise several jurisdictional arguments under McGirt that are so inadequate and clearly unresearched that any reasonable attorney would know they lack merit. Plaintiff repeatedly asserts that if this court fails to direct bar disciplinary proceedings in Illinois, that it is effectively “overturning” McGirt v. Oklahoma, 140 S.Ct. 2452 (2020), a case where the United States Supreme Court held that the entirety of the Eastern District of Oklahoma is “Indian Country” for the purposes of the Major Crimes Act. Dkt. No. 74 at ¶44. Plaintiff also claims that Judge White wrote the McGirt opinion (he did not), indicating that counsel has not made any attempt to research the case. Id. In addition, plaintiffs further allege that “the Defendants accused Plaintiff Lowery of a violation of the Major Crimes Act while on an Indian reservation land under McGirt … Therefore, if the Court wants to exercise jurisdiction under McGirt it would be Mandatory jurisdiction.” Lowery III, Dkt. No. 22 at p. 5. OMNIBUS ORDER
Takeaways
- Even if an LLM feels like it gives you an overview of the data, look at the data. There’s fun stuff in there and you’ll catch more hallucinations.
- But you should also ask if you should even be using LLMs for a given data analysis task. Pivot tables and SUM functions still exist.
- Your starting assumption should be that every map is a population map.
- Damien’s database is legit.
- Come at the Midwest, better not miss.